Intro to parallel computing
Parallel programming in Chapel
Chapel provides high-level abstractions for parallel programming no matter the grain size of your tasks, whether they run in a shared memory or a distributed memory environment, or whether they are executed “concurrently” (frequently switching between tasks) or truly in parallel. As a programmer you can focus on the algorithm: how to divide the problem into tasks that make sense in the context of the problem, and be sure that the high-level implementation will run on any hardware configuration. Then you could consider the specificities of the particular system you are going to use (whether is shared or distributed, the number of cores, etc.) and tune your code/algorithm to obtain a better performance.
To this effect, concurrency (the creation and execution of multiple tasks) and locality (on which set of resources these tasks are executed) are orthogonal (separate) concepts in Chapel. For example, we could have a set of several tasks that would be running as shown below:
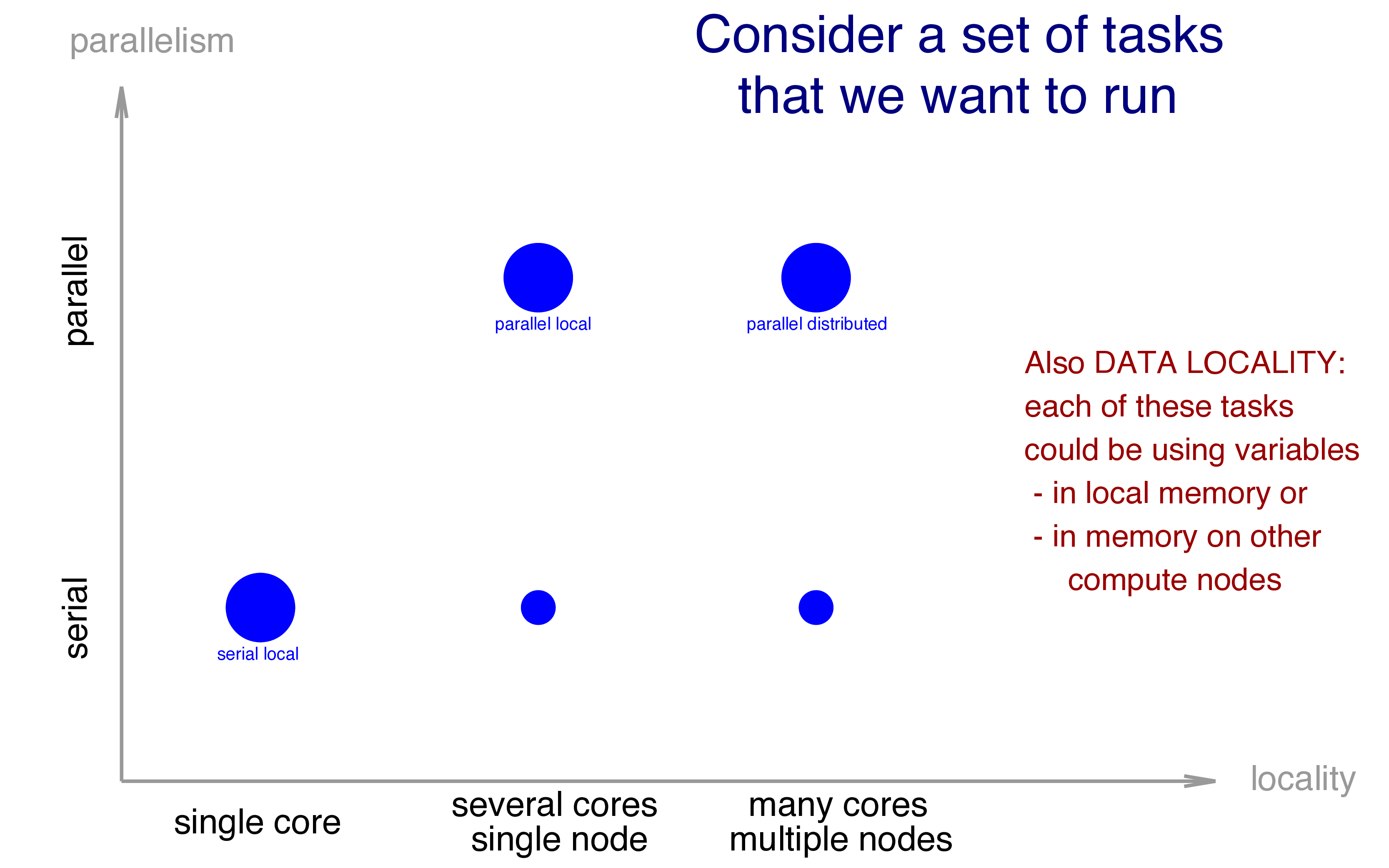
And again, Chapel could take care of all the stuff required to run our algorithm in most of the scenarios, but we can always add more specific detail to gain performance when targeting a particular scenario.
Task parallelism is a style of parallel programming in which parallelism is driven by programmer-defined tasks. This contrasts with data parallelism, where parallelism is driven by computations over collections of data elements or their indices.
Chapel provides functionality for both task- and data-parallel programming. Since task parallelism is lower level (you tell the computer how to divide your computation into tasks with statements such as begin, cobegin, coforall) than data parallelism, it is considerably more difficult. In this course we will focus mostly on data parallelism, but we will briefly cover task parallelism towards the end of the course.
Running single-local parallel Chapel
Make sure you are running the single-locale Chapel environment:
module load chapel-multicore/2.4.0In this lesson, we’ll be running on several cores on one node with a script shared.sh:
chpl test.chpl
srun --mem-per-cpu=3600 --cpus-per-task=4 ./testAlternatively, you can create and submit a Slurm script:
#!/bin/bash
#SBATCH --time=0:5:0 # walltime in d-hh:mm or hh:mm:ss format
#SBATCH --mem-per-cpu=3600 # in MB
#SBATCH --cpus-per-task=4
#SBATCH --output=solution.out
./test